
FRED was the most popular disk magazine for the SAM Coupé 8 bit home computer.Published by Colin MacDonald out of sunny Monifieth, Scotland, the magazine ran from it's first issue in 1990 through to it's last (82) in 1998.
For the SAM networking project I was hoping there might be some information on how the network worked in one of the issues -- maybe someone had done the groundwork for me. Disk images for all issues are available on World of Sam and can be loaded up in the emulator. But that made it hard to find anything specific -- you'd have to load up each disk, page through the magazine hoping not to nod off before you found what you're looking for. It would be easier if I could say search for "network" and find the issues where it was mentioned.
So I set about extracting the text files from the magazine -- which in this case meant re-implementing the decoder. If you find that kind of thing interesting, read on!
The extracted magazine text files (with addresses, etc. redacted) are now available on World of Sam!
FRED magazine
Each issue of FRED (from 4 onwards) had at least 2 text slots on the disk -- the editorial and the letters/reviews. These were viewable within readers on the disk, reachable from the main menu in slots A & B.
 FRED 28 Main Menu Christmas '92 - the first issue of FRED I got with my Sam
FRED 28 Main Menu Christmas '92 - the first issue of FRED I got with my Sam
Early issues of the magazine are in plain text (SAM Coupé ASCII) stored as simple data files with all pages in consecutive order. The following snippet is from FRED 16 the last issue with the Axe plain text reader.
Freditorial
Greetings one and all from bonny Scotland (Och Aye The noo!)
A free FRED to the first person who can tell me what it
means!! Coming up to Xmas you'd expect loadsa new SAM games
wouldn't you. Unfortunately, the only one I think MIGHT be out
in time for Xmas is Prince Of Persia! Although I did say last
month that it had been released it seems there was a slight
miscalculation at Revelation (mmmm..that makes a change).
Each line is wrapped at 64 characters, with line-ends padded out to the full 64 characters. Blank lines are not empty and contain 64 space characters, including when they're at the end of the page. This is obviously pretty wasteful for memory/disk space, but has the advantage that each page takes up precisely the same amount of space, making paging forwards and backwards very easy. Displaying the text on the screen is simply a case of starting reading at page * page_size and dumping the correct amount of chars to screen.
Each page of text is 21 lines long, leaving a bit of space for controls (the heading is part of the text). That means each page is 21 * 64 = 1344 bytes long. A magazine 20 pages long would take 26,880 bytes or 26.25 KB. As the magazine grew, particularly the letters & reviews pages, this would take up an increasing % of the limited disk space (780 KB per issue), leaving less space for software. The solution was the new compressing Entropy Reader by Simon Cooke.
Entropy Reader
The Entropy Reader was used on FRED issues 17 (1992) onwards, right up to the final issue -- although it was tweaked a few times in between. Magazine text was compressed down to data files on disk by a compressor and then decompressed back to memory by the reader.
Starting this project I had no idea of the compression scheme. There are two simply ways to compress data -- tokenization and run-length encoding. The first uses a substitution table, where you can replace a entire word, or parts of words, with a control code. This relies on either calculating or knowing the most common words in the text. The second substitutes runs of identical characters with another. This isn't usually very effective in text because the occurrence of repeated letters is pretty low1.
 FRED 17 Magazine the first issue with the Entropy Reader
FRED 17 Magazine the first issue with the Entropy Reader
The magazine is stored in .mag files, separate from the reader program. There reader program was included on disk and didn't change between issues, although there were 3 variants through the lifetime of FRED magazine. Opening the data files in a hex editor gives the following garbled plaintext.
FRED manšmĂ.t accept noÂ.PontardawĂšÂ.Ăsponsibil
fĂĂ
injuriesÂ.Swans
òÂincuÜâ try° ĂĂ
ÂśnoĂcĂšÂWalesÂ.Ăis line.ĂÂUAnybodĂşĂmemĂ
r a l¸ablĂšlĂľtlĂšgamĂšon Âold SĂŞccĂşcallâBouldĂdaĂĂ If soĂyou§suĂĂ
Ă plòsâ Ă hòr Ăá a SAMgamesimilarĂ
ĂĂ
Ăis tyĂŞ is jĂ t about Ăady
ĂÂŽÂmomĂ.t ĂľgoesĂ
bĂş ÂnamĂšof "Wop Gamma"ĂĂis is jĂt a wĂk° tĂľle,a
ĂŻaĂntĂ
In amongst the nonsense control codes there are clearly readable parts of words. The name of a game "Wop Gamma" is readable in it's entirety, as is the country "Wales", but the city Swansea appears as Swansò and consists of the following bytes.
s w a n s (242) (128) (22)
Skipping through the file we can see other similar substitutions e.g.
Simon Cooke -> S i m o n C (227) k e subscribers -> s u b s c r i (217) r s I've finally started getting -> I'v (249) f i n a l (209) s t a r t (226) g e t t (176)
From this we can start building a substitution table
| Dec | Hex | Substitution |
|---|---|---|
| 176 | B0 | ing |
| 177 | B1 | een |
| 195 | C3 | er |
| 208 | D0 | ly |
| 209 | D1 | th |
| 217 | D9 | be |
| 221 | DD | re\s |
| 222 | DE | en |
| 226 | E2 | ed |
| 227 | E3 | oo |
| 241 | F1 | d\sd |
| 249 | F8 | e\s |
| 251 | FB | ic |
It doesn't look like there is any particular pattern here, but maybe something will come out.

To support developers in [[ countryRegion ]] I give a [[ localizedDiscount[couponCode] ]]% discount on all books and courses.
[[ activeDiscount.description ]] I'm giving a [[ activeDiscount.discount ]]% discount on all books and courses.
The reader program
We could carry on like this manually, building the table. But there are two problems -- (1) it's boring, (2) if the substitutions vary between issues, we'll have to do that again.
Thankfully, we don't need to do that. The FRED disks contain the reader program DOCREADER. As well as providing the reader interface, this program is responsible for decompressing the data back to plain text in memory -- meaning the code must contain the substitution table somewhere.
Opening the DOCREADER program in a hex editor, we can see a block that looks interesting.
addressÂscreensÂscreen issueÂmemoryÂscreen don
't SAMCO SAMCoÂCoupe FREDÂbytes data it's from SAM 19šcodeÂ
CodeÂDataÂould out hadÂCoupĂĽSAMCĂSAMCĂŻTheÂtheÂtioĂŽ atÂempĂ´19šc
omĂ°ComĂ°conĂłConĂł. yoĂľ'llÂereÂYou itÂ.)Ân'Ă´itĂšAtÂ19šinçeeĂŽanĂ
¤AnäghĂ´maçprĂŻouĂovĂĽagĂĽ -Â'mÂ'sÂYoĂľ IÂanĂ´iaĂŹ  ¨eò, Â.Â!Â?Â
AÂoòsĂłeĂĽcèsèuĂŽlĂštèTèTĂŻtĂŻoáqĂľQĂľBĂĽbĂĽUĂ°uĂ°RĂĽrĂĽeĂŽEĂŽuĂłU
Ăłeäo ĂŻ.¢!¢?¢;Â:Â)ÂpĂĽPĂĽiòIòmĂšpĂ°IÂdäeĂĄfĂŚsĂłiĂ´ròaĂ´AĂ´eÂ
yÂiĂŁ
The most obvious block is beginning with the word address (3rd line). This consists of a series of words delimited with hex A0 (dec 160)2. But this isn't the same partial substitutions we found earlier. If these worked in the same way, we would be able to find them in the reader code -- for example, the longest partial string we found ing. But it isn't there (neither is ly, except in plaintext help message at the end). So, something is going on here.
At the beginning of the block we see a series of single letters and numbers (but not all the letters and numbers) arranged, separated by hex 01 (dec 1). Notice that the list includes all vowels -- my first thought was that this is a list of the most common letters in English, though why we'd be substituting single characters is a mystery.
Converting
Despite the unanswered questions, we have enough information to get started on our converter. First, we can get whole-word substitution map from the DOCREADER with the following code (byte offsets hardcoded for now):
with open('DOCREADER', 'rb') as f:
data = f.read()
#Âdata is bytestring, isolate substitutions (byte 918 onwards)
data = data[918:918+222]
subs = data.split(b'\xa0')
print(subs)
Which produces the following output.
[b'address', b'screens', b'screen', b' issue', b'memory', b'screen', b" don't", b' SAMCO', b' SAMCo', b'Coupe', b' FRED', b'bytes', b' data', b" it's", b' from', b' SAM', b'\x7f 19\xb9code', b'Code', b'Data', b'ould', b' out', b' had', b'Coup\xe5SAMC\xcfSAMC\xefThe', b'the', b'tio\xee at', b'emp\xf4\x7f19\xb9com\xf0Com\xf0con\xf3Con\xf3.', b" yo\xf5'll", b'ere', b'You', b' it', b'.)']
We don't know the substitution codes for these yet, but we can compare the output of DOCREADER with the input mag file to work them out. Loading up FRED 28 we don't need to look far to find a match -- issue is in the first line.
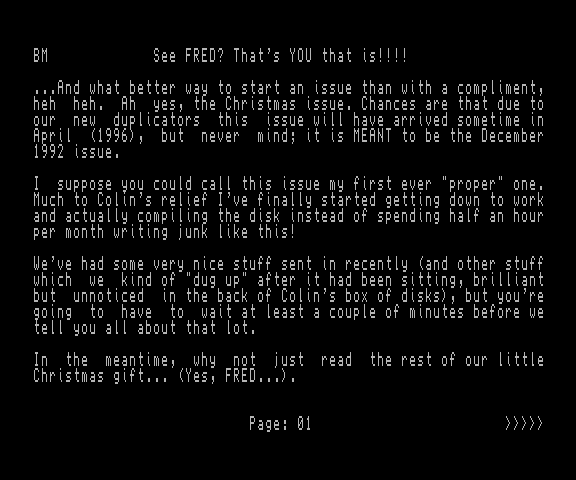 FRED 28 Magazine with the reader showing the first page.
FRED 28 Magazine with the reader showing the first page.
The text reads:
...And what better way to start an issue than with a compliment, heh heh. Ah yes, the Christmas issue.
The word issue is in our substitution table, and appears twice on the first page. Here is the data from the mag file.
FREDĂĂáŸYOU Ăá is!!!ĂÂP.Âł whá ĂttĂ waúà start anÂĂan wĂľh
a ÂĄlimĂ.t,hehĂ
hehĂ AhĂ
yesĂÂChristmas iĂueĂ
The first issue is substituted with 84 (dec 132) , start anÂĂan (it must be the first character after the first 'an'). The second isn't substituted, but instead has it's double-s substituted with CB (dec 203). This suggests the word substitution only works on isolated 'whole words' surrounded by space -- the second issue is followed by a full-stop and a space, which has been substituted by C6 (dec 198). That gives us a few more manual entries for the substitution table.
| Dec | Hex | Substitution |
|---|---|---|
| 188 | BC | 's\s |
| 203 | CB | ss |
| 198 | C6 | .\s |
I would expect the word substitution table to be stored ordered in the reader file (so the next word uses a code 1 greater than the previous). To check this we can assign the codes in order and then compare another of the substituted words that appears multiple times -- for example the which is replaced with 9C (dec 156).
The following will assign the codes in order from 129 up to however many items there are in subs.
dec = range(129, 300) # too long, will truncate
word_map = dict(zip(dec, subs))
print(word_map)
Which gives the following output...
{129: b'address', 130: b'screens', 131: b'screen', 132: b' issue', 133: b'memory', 134: b'screen', 135: b" don't", 136: b' SAMCO', 137: b' SAMCo', 138: b'Coupe', 139: b' FRED', 140: b'bytes', 141: b' data', 142: b" it's", 143: b' from', 144: b' SAM', 145: b'\x7f 19\xb9code', 146: b'Code', 147: b'Data', 148: b'ould', 149: b' out', 150: b' had', 151: b'Coup\xe5SAMC\xcfSAMC\xefThe', 152: b'the', 153: b'tio\xee at', 154: b'emp\xf4\x7f19\xb9com\xf0Com\xf0con\xf3Con\xf3.', 155: b" yo\xf5'll", 156: b'ere', 157: b'You', 158: b' it', 159: b'.)'}
With issue lined up at 132, that gives 152 for 'the', rather than the 156 we wanted. Bugger.
But there are a few weird entries in there, containing something other than plain text -- other codes > 127 ASCII in the table, e.g. Coup\xe5SAMC\xcfSAMC\xefThe, and what's yo\xf5'll? There is some additional structure to this lookup table that I'm missing so far. Pressing on I identified a few more manual entries.
| Dec | Hex | Substitution |
|---|---|---|
| 176 | B0 | ing |
| 177 | B1 | een |
| 178 | B2 | and |
| 179 | B3 | And |
| 180 | B4 | ght |
| 181 | B5 | mag |
| 182 | B6 | pro |
| C5 | double space |
As substitutions are added it becomes progressively easier to map the remaining letter groups. For example
N\xf7ural Disasters - Earth\xd6ake and Typhoon\xba for
It's obvious that 0xD6 is "qu" and 0xF7 is "at". After a few more manual assignments to the table we're getting there, and the text is almost readable.
Stevie T forgotten to write it? Has he been kidnapped by a gangof rebellious tin-openers? Or is our postal system simplyfalling to pieces? Who knows? \xd3 make up for this utter tragedy,we\'ve decided to rewardyou all for being such loyal readers by(a) being \xcfnecessarily corny and ingratiating and (b) by givingyou part 2 of "Rachel! Now, canyou honestly say we\'re not goodtoyou? (Andyou\'d better be thinking "Gosh, how jolly generous"otherwise we will NOT be pleased).
In some places the words are run together. Some of these e.g. BrianMcConnell are due to the word-wrapping on the SAM Mode 3 screen -- no space is inserted at the end of a line. But in others e.g. goodtoyou it's a problem -- the "to" might probably be "to " to "you" to " you". There is no way to check these bar comparing with the output of the reader line by line, and this is getting a bit tedious.
At this point I thought I'd go looking for the source code for the compressor/reader, but landed on something far more helpful -- documentation3. It's even rather good.
The compressor
Below is a snippet from the documentation.
Document text in a MAG file is compressed using a combination of run-length compression and tokenised strings. Each page is 1344 bytes long (64 characters per line, 21 lines per page). Data bytes below 128 are passed directly to the output routine, bytes with the value 128 are passed onto the run-length subroutine, and the rest (129-255) are passed onto the detokenisation routine. Arguably, better compression could be provided by allowing tokens to also have the value 0-31 -- increasing the total number of tokens available from 127 to 159 -- but as this is not done by the Document Reader, and there are no further incarnations of the original reader program planned, this is a moot point.
So, the compressor actually uses both tokenisation and run-length compression, but the run-length applies only to spaces in the text. That explains why it wasn't more noticeable in the generated output.
The compressor works by looking for a string of 3 or more spaces in the document text. so this can lead to considerable savings). Thus, whenever a code of &80 hex is found in the compressed text, the next byte is taken, and this is used as a counter to print spaces to the screen. Occurences of two consecutive spaces are compressed by the tokenising routine.
This last point makes sense because run-length encoding would compress a 2-space block to 2 bytes, a waste of time [space-marker][2], while replacing 2 spaces with a 1 byte token nets a (small) saving.
The run-length encoding is simple to implement in Python, the code below gives an example. We read a byte at a time, if the the byte has a value of 128 (80 hex) it's a space marker. We read the next byte and add that many spaces to the output, skipping ahead an extra byte.
result = b''
i = 0
while i < len(data):
byte = data[i]
if byte == 128:
# Run length compression, get another byte.
i += 1
length = data[i]
result += b' ' * length
else:
char = sub_map.get(
byte,
bytes([byte])
) #Âsubstitute if exists, fallback to existing.
result += char #.decode('utf8')
i += 1
print(result)
The addition of the run-length decompression makes the text look a lot more like it should, here wrapped at 64 characters.
In eremeantime though, Merry Christmas, and\xbehopeyou all getn
ice FRED software articles inyour stockings\xc7
BM Credits
Editor:- Brian McConnell
Publisher:- FREDPublishing
T
hanks this month to:-
Charles Hawes\xc1\xd8n Wyatt
Calvin Allett\xc1Banzai\xc7
Mork\xc7 Hipposoft
Simon Cooke BTB
Steve Taylor\xc1Ian Slavin
Andy Monk\xc1Electron Aff in\xad
REMEMBER:-\xc1 yo\xf5\'llexpression "kill 2 birds wit
h one stone" is notmeant to be taken literally. It is, however,
quite easy, ifyoucatch them in a large net first\xa5
The eremeantime looks a mis-tokenisation by me and there are others. The documentation actually contains a copy of the entire substitution table(!) but it would still be nice to be able to extract this directly from the MAG file -- it'll allow us to decompress magazines without knowing which version of the reader they are using.
Thankfully the documentation gives a hint where I was going wrong.
If a token is found, 129 is added to the token's dictionary reference number, and it takes the place of the equivalent text in the compressed data. Thus all it's necessary to do to decompress the tokens, is to have a copy of the appropriate dictionary, and then to use the token data to access that table.
...and...
Each token has bit 7 set on the last character, to mark that the end of the token has been reached.
This explains what's going on with the substitution table and why we couldn't just split it using 0xA0. The last character of each entry in the table has it's high (127) bit set. The value 0xA0 is actually a space 0x20 (dec 32) with it's high bit set (0x80 + 0x20 = 0xA0)
Some of the tokens end with a space, others do not!
With that crucial bit of information we can now parse the token table out of the reader file. We can start iterating from the some position (here 129, which I think is the beginning of the table) and look for the high bit of a byte to be set, using byte & 0x80.
data = data[918:918+408]
tokenix = 129 # tokens start at 129.
tokens = {}
token = b''
i = 0
while i < len(data):
byte = data[i]
if byte & 0x80:
# High bit set, subtract, store, and get ready for next token.
byte -= 0x80
token += bytes([byte])
tokens[tokenix] = token
tokenix += 1
token = b''
else:
token += bytes([byte])
i += 1
print(tokens)
This generates the following complete token table, with "the" assigned the expected value of 156.
{129: b'address ', 130: b'screens ', 131: b'screen ', 132: b' issue ', 133: b'memory ', 134: b'screen ', 135: b" don't ", 136: b' SAMCO ', 137: b' SAMCo ', 138: b'Coupe ', 139: b' FRED ', 140: b'bytes ', 141: b' data ', 142: b" it's ", 143: b' from ', 144: b' SAM ', 145: b'\x7f 199', 146: b'code ', 147: b'Code ', 148: b'Data ', 149: b'ould ', 150: b' out ', 151: b' had ', 152: b'Coupe', 153: b'SAMCO', 154: b'SAMCo', 155: b'The ', 156: b'the ', 157: b'tion', 158: b' at ', 159: b'empt', 160: b'\x7f199', 161: b'comp', 162: b'Comp', 163: b'cons', 164: b'Cons', 165: b'. ', 166: b' you', 167: b"'ll ", 168: b'ere ', 169: b'You ', 170: b' it ', 171: b'.) ', 172: b"n't", 173: b'ity', 174: b'At ', 175: b'199', 176: b'ing', 177: b'een', 178: b'and', 179: b'And', 180: b'ght', 181: b'mag', 182: b'pro', 183: b'oum', 184: b'ove', 185: b'age', 186: b' - ', 187: b"'m ", 188: b"'s ", 189: b'You', 190: b' I ', 191: b'ant', 192: b'ial', 193: b' ', 194: b' (', 195: b'er', 196: b', ', 197: b' ', 198: b'. ', 199: b'! ', 200: b'? ', 201: b'A ', 202: b'or', 203: b'ss', 204: b'ee', 205: b'ch', 206: b'sh', 207: b'un', 208: b'ly', 209: b'th', 210: b'Th', 211: b'To', 212: b'to', 213: b'ow', 214: b'qu', 215: b'Qu', 216: b'Be', 217: b'be', 218: b'Up', 219: b'up', 220: b'Re', 221: b're', 222: b'en', 223: b'En', 224: b'us', 225: b'Us', 226: b'ed', 227: b'oo', 228: b'."', 229: b'!"', 230: b'?"', 231: b'; ', 232: b': ', 233: b') ', 234: b'pe', 235: b'Pe', 236: b'ir', 237: b'Ir', 238: b'my', 239: b'pp', 240: b'I ', 241: b'dd', 242: b'ea', 243: b'ff', 244: b'ss', 245: b'it', 246: b'rr', 247: b'at', 248: b'At', 249: b'e ', 250: b'y ', 251: b'ic'}
Running this substitution table and the run-length encoding against the compressed text, produces the following perfectly decompressed output.
Colin "Fuhrer" Macdonald here has just ordered me to point outthat you, the reader, should always make cheques payable to FREDPublishing. Some people, you see, have been practising what canonly be called "creative cheque writing", and have been makingthem out to all sorts of strange companies like FRED SoftwareLtd., and Belgian Massage Inc., (okay, so the last one was ajoke. As far as I know, anyway).
Page wrap
Each page is 1344 bytes long (64 characters per line, 21 lines per page). So far we've been ignoring line breaks but to get completely readable text we need to add them in.
Splitting lines is simply a case of iterating through the data, in 64 byte chunks, but first we need to be sure we have the correct start position in the data file. For v1.1 and v1.2 the files have a short header which contains the offset at which the data starts. The following will extract and calculate this offset for us (based on the documentation).
offset = int.from_bytes(data[0:2], byteorder='little') - 38233
Using this as our start position we can now iterate forwards in 64 byte blocks to get well-formatted output.
b'BM News '
b' '
b"The biggest piece of news this month is that you don't have to"
b"put up with a knackered SAM anymore!! (Although, if your SAM's"
b"knackered I don't know how you're supposed to read this and find"
b'out. Hmmm). Yes, those two faithful SAM people Adrian Parker'
b'(from MGT, Blue Alpha, and SAMCo) and Mark Hall (from MGT, SAMCo'
b'and SAMTech) have joined together and resurrected Blue Alpha'
b'Electronics! Already in operation, this "new" company can now'
b"repair all those little problems you've been bothered by. Prices"
b'for repairs are:- '
b' '
b'SAM (not including disk drive) - `30 '
b'Interfaces - `18 '
b'Disk Drive - `18 '
The text above shows all the remaining trailing spaces in place, but we could also truncate the lines.
We also need to insert blank lines at the end of every page for readability -- since the original reader displayed the text page by page, it is possible for there to be text at the very bottom of one page that would run against the header on the following page. It's not a disaster, but it's ugly. To solve this we can just count every 21 lines and insert a blank (empty) line into the output.
Finally, can now convert our text to strings and make some simple substitutions to account for the differences between the SAM Coupé ASCII table and UTF-8.
.replace('\x5E', '↑') # is ^ by default,
.replace('\x5F', '_')
.replace('\x60', '£')
.replace('\x7F', '©')
The output is now ready to be written to text files.
Create GUI Applications with Python & Qt6 by Martin Fitzpatrick — (PySide6 Edition) The hands-on guide to making apps with Python — Over 10,000 copies sold!
Different versions
If all the versions of the reader were the same, this would be the end of the matter. But there are actually 3 different versions used on FRED magazine. The different versions all use different subsitution tables, store them in slightly different locations in the file, and change the format of the mag file header.
To handle these cases two alternatives were added to the converter --
- if the original reader executable is available, this can be passed to the converter and will be used as the source for the dictionary. This table is located in different places in the different versions, so a series of long probably-unique bytes are used to find the table -- there are limited versions out there, so this is fine
- the known dictionaries are included in the converter, and can be specified from the command line
Final steps
With these modifications it was possible to convert all the FRED magazine text (and letters, and other content) to plaintext, with the following steps --
- the FRED magazine DSK files were downloaded
- the magazine text and reader files were extracted from the the disk images using samfile then copied to a series of folders
- the files were processed to plain text, passing in the reader file for the specific magazine
The screader converter tool has been released as a Python package. You can install it with
pip3 install screader
Run the tool with screader -h to get the command line help.
screader -h
usage: screader [-h] [--reader READER] [--readerversion {0,1,2}] [--skipinstructions] [--format {text,markdown}] [--outfile OUTFILE]
mag [mag ...]
Extract Sam Coupe Entropy Reader files.
positional arguments:
mag source MAG file(s) to process.
optional arguments:
-h, --help show this help message and exit
--reader READER, -r READER
Path to the reader executable (token table will be extracted).
--readerversion {0,1,2}, -rv {0,1,2}
Version of compressor token table to use (0, 1, 2 for v1.0, v1.1, v1.2 respectively).
--skipinstructions, -s
Skip first page (instructions)
--format {text,markdown}, -f {text,markdown}
Output format, one of (text, markdown).
--outfile OUTFILE, -o OUTFILE
Output file (filename will be used for format, if not specified with -f. Output to <infile>.txt if not provided.)
You can see the full source code on Github.
Uploading
Once all the files were converted to plaintext, the content was uploading onto World of Sam, the home of all things SAM Coupé. For an example see FRED28 --- scroll down for the magazine text. You can find all issues of FRED here.
Each magazine was manually redacted to remove personal info such as addresses, email addresses (later) and phone numbers. This was by far the most time-consuming part of the process, as it wasn't fully automatable. I just read the lot and built a table of regex searches for things that look like addresses, in case I'd nodded off the first time. Hopefully I got them all.
I still haven't got to the issues < 17 -- which are arguably simpler, since they're just in plain text. Something for a rainy day.
...and the Network?
No, I didn't find anything about the network, beyond what was already on World of Sam.
Oh well.
PyQt/PySide 1:1 Coaching with Martin Fitzpatrick — Get one on one help with your Python GUI projects. Working together with you I'll identify issues and suggest fixes, from bugs and usability to architecture and maintainability.